
Configuration drift is expensive
Teams deploy workloads without resource limits, skip health probes, run containers as root, and forget PodDisruptionBudgets. Each one is a small risk. Together, they add up to outages, security gaps, and wasted spend.
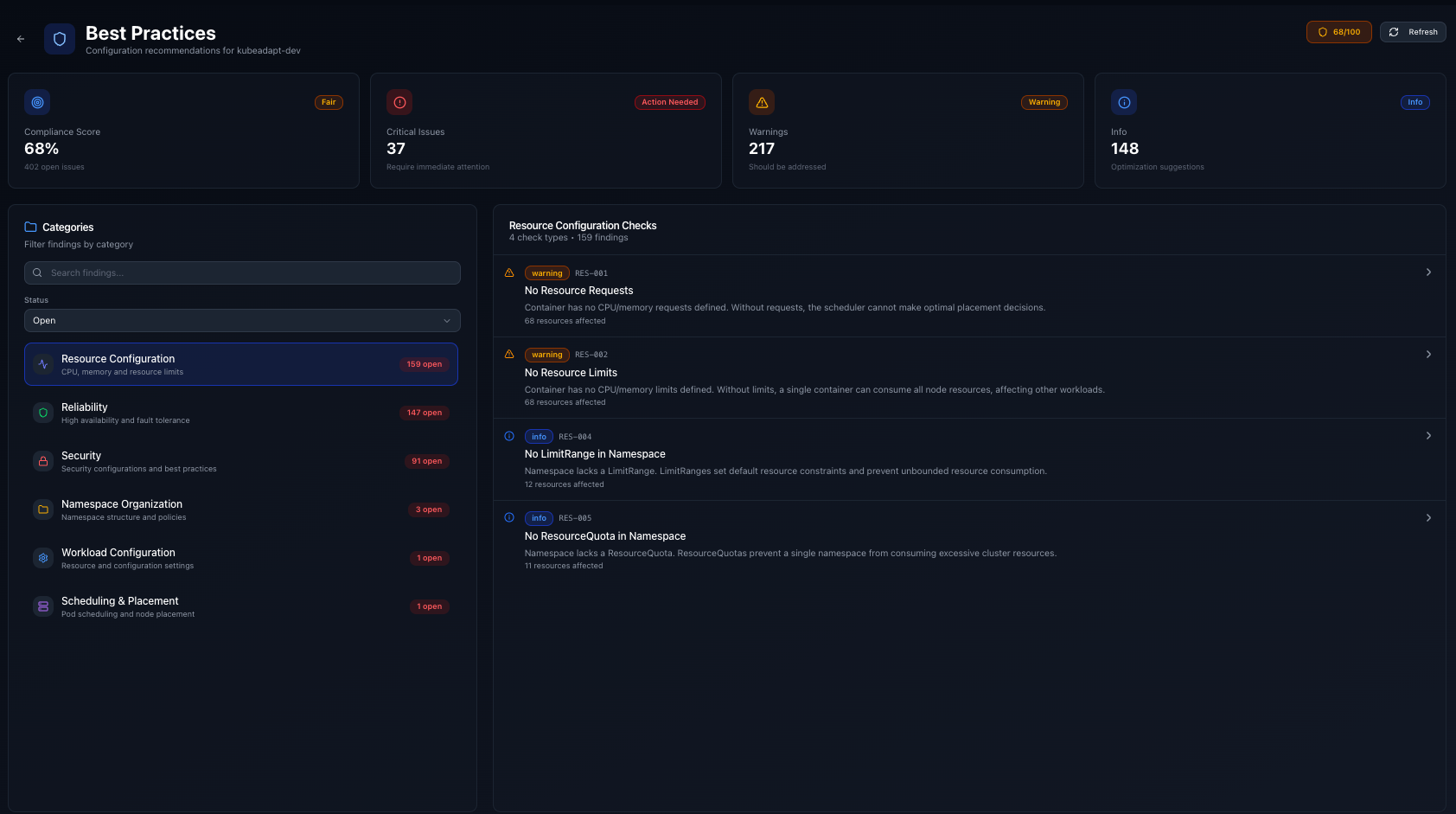
Kubeadapt now audits every workload in your cluster against 50+ best practice rules and gives you a prioritized list of what to fix.
What gets checked
Checks are grouped into seven categories:
- Security: running as root, privilege escalation, read-only filesystem, seccomp profiles
- Reliability: liveness and readiness probes, PodDisruptionBudgets, replica counts
- Resource configuration: missing requests/limits, CPU limit anti-patterns, memory limit coverage
- Workload configuration: image pull policy, tag pinning, restart policy
- Scheduling: topology spread, anti-affinity, node selectors
- Storage: volume mount permissions, ephemeral storage limits
- Namespace: resource quotas, limit ranges
Each finding has a severity (critical, warning, info) and a remediation description explaining what to change and why.
Compliance score
Your cluster gets a compliance score from 0 to 100, weighted by severity. Critical findings pull the score down more than warnings. The score updates with every agent snapshot, so you can track improvement over time.
How to use it
Go to Cluster > Best Practices in the dashboard. You'll see the overall score, a breakdown by category, and a list of findings sorted by severity. Click any finding to see affected workloads and the recommended fix.